Map
01.Map
01.map底层
- [参考(opens new window)](https://www.bookstack.cn/read/qcrao-Go-Questions/map-map 的扩容过程是怎样的.md)
1.1 map底层浅析
- 笼统的来说,go的map底层是一个hash表,通过键值对进行映射
- 键通过哈希函数生成哈希值,然后go底层的map数据结构就存储相应的hash值,进行索引,最终是在底层使用的数组存储key,和value
- 稍微详细的说,就设计到go map 的结构:
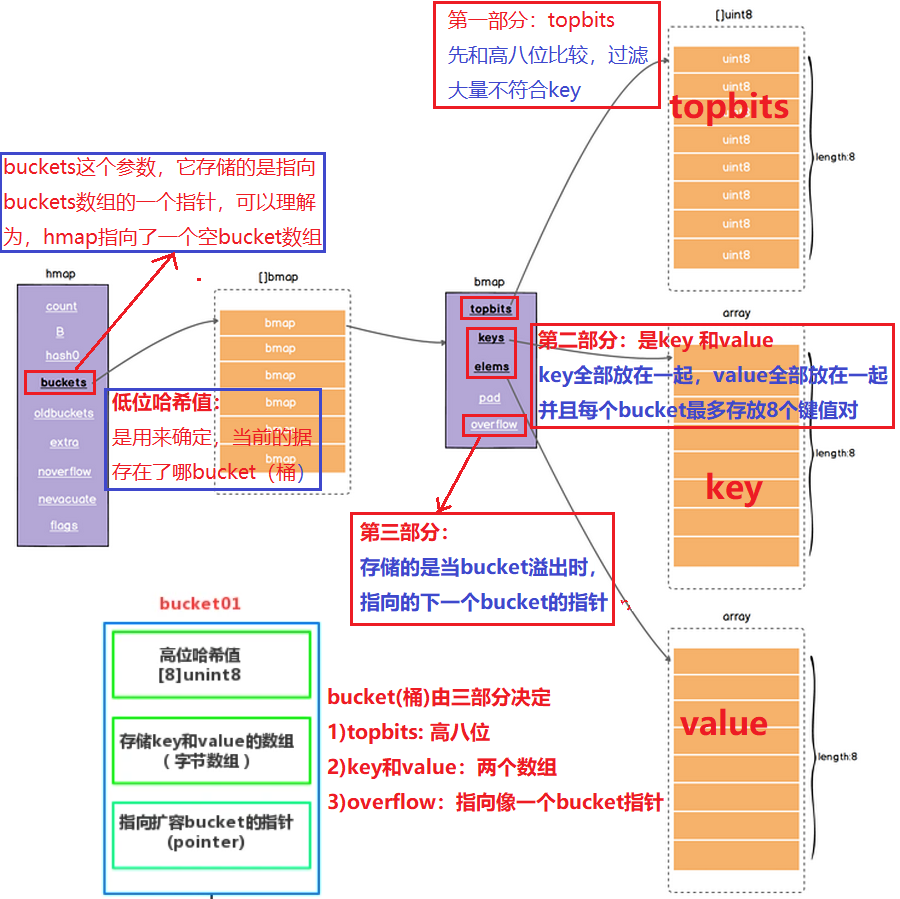
hmap 和bmap
1.2 Hash函数
哈希函数会将传入的key值进行哈希运算,得到一个唯一的值。
go语言把生成的哈希值一分为二,比如一个key经过哈希函数,生成的哈希值为:
8423452987653321,go语言会这它拆分为84234529,和87653321。那么,前半部分就叫做
高位哈希值
,后半部分就叫做
低位哈希值
。
- 高位哈希值:是用来确定当前的bucket(桶)有没有所存储的数据的。
- 低位哈希值:是用来确定,当前的数据存在了哪个bucket(桶)
02.map源码
2.1 hmap(a header of map)
- hmap是map的最外层的一个数据结构,包括了map的各种基础信息、如大小、bucket。
- 首先说一下,buckets这个参数,它存储的是指向buckets数组的一个指针,当bucket(桶为0时)为nil。
- 我们可以理解为,hmap指向了一个空bucket数组,并且当bucket数组需要扩容时,它会开辟一倍的内存空间
- 并且会渐进式的把原数组拷贝,即用到旧数组的时候就拷贝到新数组。
// Go map的一个header结构
type hmap struct {
count int // map的大小. len()函数就取的这个值
flags uint8 //map状态标识
B uint8 // 可以最多容纳 6.5 * 2 ^ B 个元素,6.5为装载因子即:map长度=6.5*2^B
//B可以理解为buckets已扩容的次数
noverflow uint16 // 溢出buckets的数量
hash0 uint32 // hash 种子
buckets unsafe.Pointer //指向最大2^B个Buckets数组的指针. count==0时为nil.
oldbuckets unsafe.Pointer //指向扩容之前的buckets数组,并且容量是现在一半.不增长就为nil
nevacuate uintptr // 搬迁进度,小于nevacuate的已经搬迁
extra *mapextra // 可选字段,额外信息
}2.2 bmap(a bucket of map)
- bucket(桶),每一个bucket最多放8个key和value,最后由一个overflow字段指向下一个bmap
- 注意key、value、overflow字段都不显示定义,而是通过maptype计算偏移获取的。
// Go map 的 buckets结构
type bmap struct {
// 每个元素hash值的高8位,如果tophash[0] < minTopHash,表示这个桶的搬迁状态
tophash [bucketCnt]uint8
// 第二个是8个key、8个value,但是我们不能直接看到;为了优化对齐,go采用了key放在一起,value放在一起的存储方式,
// 第三个是溢出时,下一个溢出桶的地址
}- bucket这三部分内容决定了它是怎么工作的
第一部分:tophash- 它的tophash 存储的是哈希函数算出的哈希值的高八位是用来加快索引的。
- 因为把高八位存储起来,这样不用完整比较key就能过滤掉不符合的key,加快查询速度
- 当一个哈希值的高8位和存储的高8位相符合,再去比较完整的key值,进而取出value。
第二部分:存储的是key 和value- 就是我们传入的key和value,注意,它的底层排列方式是,key全部放在一起,value全部放在一起。
- 当key大于128字节时,bucket的key字段存储的会是指针,指向key的实际内容;value也是一样。
- 这样排列好处是在key和value的长度不同的时候,可以消除padding带来的空间浪费。
- 并且每个bucket最多存放8个键值对
第三部分:存储的是当bucket溢出时,指向的下一个bucket的指针- bucket的设计细节:
- 在golang map中出现冲突时,不是每一个key都申请一个结构通过链表串起来
- **而是以bmap为最小粒度挂载,一个bmap可以放8个key和value。
- 这样减少对象数量,减轻管理内存的负担,利于gc。
- 如果插入时,bmap中key超过8,那么就会申请一个新的bmap(overflow bucket)挂在这个bmap的后面形成链表
- 优先用预分配的overflow bucket,如果预分配的用完了,那么就malloc一个挂上去。
- 注意golang的map不会shrink,内存只会越用越多,overflow bucket中的key全删了也不会释放
2.3 map图解
- hmap存储了一个指向底层bucket数组的指针。
- 我们存入的key和value是存储在bucket里面中,如果key和value大于128字节,那么bucket里面存储的是指向我们key和value的指针,如果不是则存储的是值。
- 每个bucket 存储8个key和value,如果超过就重新创建一个bucket挂在在元bucket上,持续挂接形成链表。
- 高位哈希值:是用来确定当前的bucket(桶)有没有所存储的数据的。
- 低位哈希值:是用来确定,当前的数据存在了哪个bucket(桶)
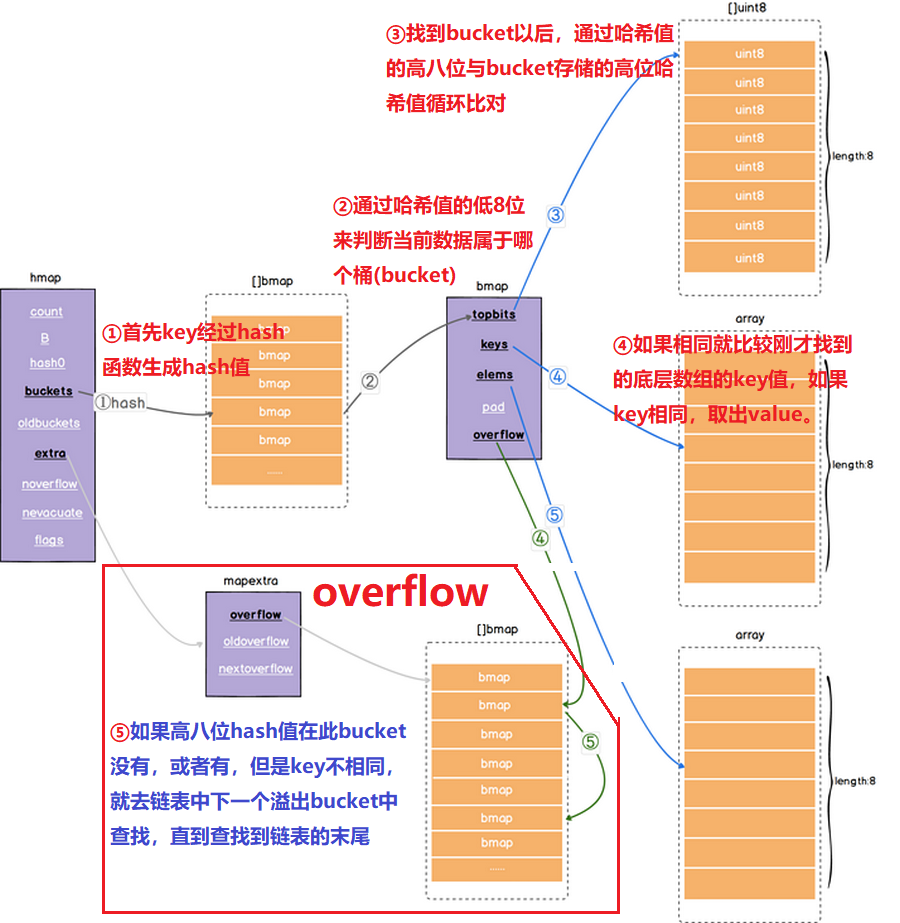
2.4 查找流程
- 查找或者操作map时,首先key经过hash函数生成hash值,
通过哈希值的低8位来判断当前数据属于哪个桶(bucket) - 找到bucket以后,通过哈希值的高八位与bucket存储的高位哈希值循环比对
- 如果相同就比较刚才找到的底层数组的key值,如果key相同,取出value。
- 如果高八位hash值在此bucket没有,或者有,但是key不相同,就去链表中下一个溢出bucket中查找,直到查找到链表的末尾
- 碰撞冲突:
- 如果不同的key定位到了统一bucket或者生成了同一hash,就产生冲突。
- go是通过链表法来解决冲突的。
- 比如一个高八位的hash值和已经存入的hash值相同,并且此bucket存的8个键值对已经满了,或者后面已经挂了好几个bucket了。
- 那么这时候要存这个值就先比对key,key肯定不相同啊,那就从此位置一直沿着链表往后找,找到一个空位置,存入它。
- 所以这种情况,两个相同的hash值高8位是存在不同bucket中的。
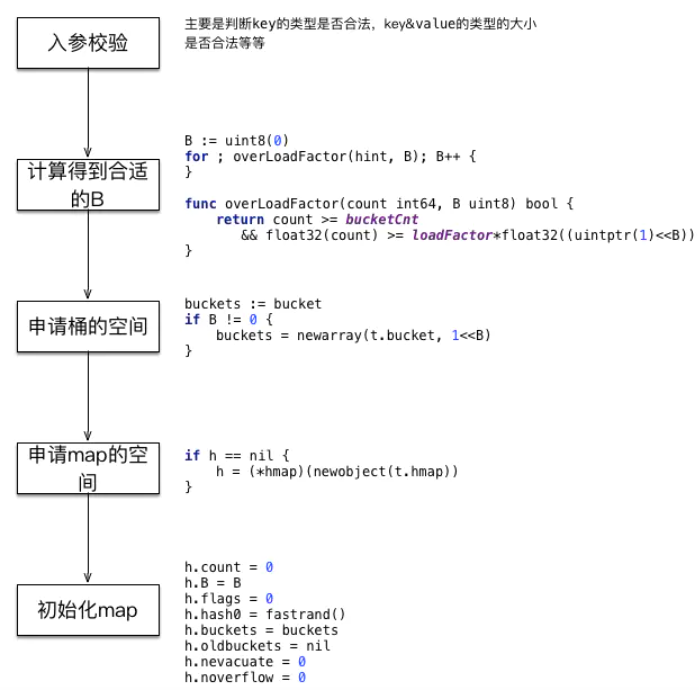
03.map增删改查原理
3.1 创建
- map的创建比较简单,在参数校验之后,需要找到合适的B来申请桶的内存空间
- 接着便是穿件hmap这个结构,以及对它的初始化。
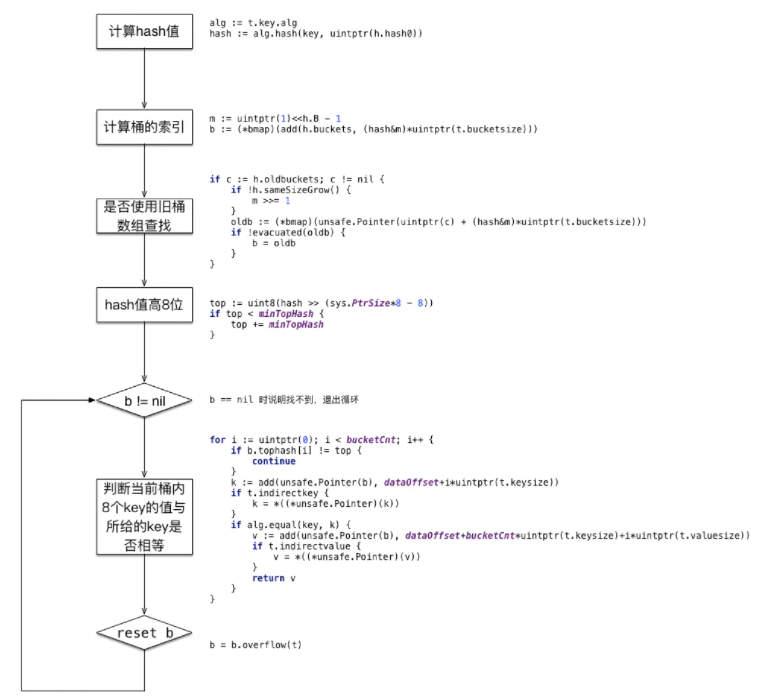
3.2 访问 - mapaccess
3.3 分配 - mapassign
- 为一个key分配空间的逻辑,大致与查找类似,但增加了写保护和扩容的操作;
- 注意,分配过程和删除过程都没有在oldbuckets中查找,这是因为首先要进行扩容判断和操作;
3.4 删除 - mapdelete
- 删除某个key的操作与分配类似,由于hashmap的存储结构是数组+链表,
- 所以真正删除key仅仅是将对应的slot设置为empty,并没有减少内存;
04.map扩容策略是什么
4.1 map简述
使用哈希表的目的就是要快速查找到目标 key,然而,随着向 map 中添加的 key 越来越多,key 发生碰撞的概率也越来越大。
bucket 中的 8 个 cell 会被逐渐塞满,查找、插入、删除 key 的效率也会越来越低。
最理想的情况是一个 bucket 只装一个 key,这样,就能达到
O(1)的效率,但这样空间消耗太大,用空间换时间的代价太高。Go 语言采用一个 bucket 里装载 8 个 key,定位到某个 bucket 后,还需要再定位到具体的 key,这实际上又用了时间换空间。
当然,这样做,要有一个度,不然所有的 key 都落在了同一个 bucket 里,直接退化成了链表,各种操作的效率直接降为 O(n),是不行的。
装载因子需要有一个指标来衡量前面描述的情况,这就是
装载因子loadFactor := count /(2^B)1 - count 就是 map 的元素个数,2^B 表示 bucket 数量 ### 4.2 触发 map 扩容的时机 - 在向 map 插入新 key 的时候,会进行条件检测,符合下面这 2 个条件,就会触发扩容 - 1)装载因子超过阈值,源码里定义的阈值是 6.5。 - 2)overflow 的 bucket 数量过多: - 当 B 小于 15,也就是 bucket 总数 2^B 小于 2^15 时,如果 overflow 的 bucket 数量超过 2^B; - 当 B >= 15,也就是 bucket 总数 2^B 大于等于 2^15,如果 overflow 的 bucket 数量超过 2^15。 #### 4.2.1 第 1 点扩容 - 我们知道,每个 bucket 有 8 个空位,在没有溢出,且所有的桶都装满了的情况下,装载因子算出来的结果是 8。 - 因此当装载因子超过 6.5 时,表明很多 bucket 都快要装满了,查找效率和插入效率都变低了。在这个时候进行扩容是有必要的。 - ``` 对于条件 1,扩容方案元素太多,而 bucket 数量太少,很简单:将 B 加 1,bucket 最大数量(2^B)直接变成原来 bucket 数量的 2 倍。
于是,就有新老 bucket 了
注意,这时候元素都在老 bucket 里,还没迁移到新的 bucket 来。
而且,新 bucket 只是最大数量变为原来最大数量(2^B)的 2 倍(2^B * 2)。
4.2.2 第2点扩容是对第1点的补充
- 就是说在装载因子比较小的情况下,这时候 map 的查找和插入效率也很低,而第 1 点识别不出来这种情况。
- 表面现象就是计算装载因子的分子比较小,即 map 里元素总数少,但是 bucket 数量多(真实分配的 bucket 数量多,包括大量的 overflow bucket)。
- 不难想像造成这种情况的原因:不停地插入、删除元素。
- 先插入很多元素,导致创建了很多 bucket,但是装载因子达不到第 1 点的临界值,未触发扩容来缓解这种情况。
- 之后,删除元素降低元素总数量,再插入很多元素,导致创建很多的 overflow bucket,但就是不会触犯第 1 点的规定
- overflow bucket 数量太多,导致 key 会很分散,查找插入效率低得吓人,因此出台第 2 点规定。
- 这就像是一座空城,房子很多,但是住户很少,都分散了,找起人来很困难。
对于条件 2,扩容方案- 其实元素没那么多,但是 overflow bucket 数特别多,说明很多 bucket 都没装满。
- 解决办法就是开辟一个新 bucket 空间,将老 bucket 中的元素移动到新 bucket,使得同一个 bucket 中的 key 排列地更紧密。
- 这样,原来,在 overflow bucket 中的 key 可以移动到 bucket 中来。
- 结果是节省空间,提高 bucket 利用率,map 的查找和插入效率自然就会提升。
05.map值无法地址取值
5.1 map指针取地址报错问题
- 当通过key获取到value时,这个value是不可寻址的,因为map 会进行动静扩容
- 当进行扩大后,map的value就会进行内存迁徙,其地址发生变化,所以无奈对这个value进行寻址
package main
type UserInfo struct {
UserName string `json:"user_name"`
}
func main() {
user := make(map[string]UserInfo)
user["0001"] = UserInfo{
UserName: "jack",
}
// 因为map会进行动静扩容,当进行扩大后,map的value就会进行内存迁徙,其地址发生变化
// 所以 user["0001"] 返回值不是固定的地址,所以无法获取地址
p1 := &user["0001"] // Cannot take the address of 'user["0001"]'
// 如果非要获取地址可以先赋值给一个变量
u := user["0001"]
p2 := &u
}5.2 map使用指针value
package main
import "fmt"
type UserInfo struct {
UserName string `json:"user_name"`
}
func main() {
user := make(map[string]*UserInfo)
user["0001"] = &UserInfo{
UserName: "jack",
}
// 上面是指针 *UserInfo 才能这样操作,否则报错
user["0001"].UserName = "tom"
fmt.Println(user["0001"])
}