内存逃逸
1.内存逃逸
01.内存逃逸
1.1 其他语言内存回收机制
- 在C/C++开发中,动态分配内存(new/malloc)需要我们手动释放资源。
- 这样做的好处是,需要申请多少内存空间可以很好的掌握怎么分配。
- 但是这有个缺点,如果忘记释放内存,则会导致内存泄漏。
- 在很多高级语言中(python/Go/java)都加上了垃圾回收机制。
1.2 什么是内存逃逸
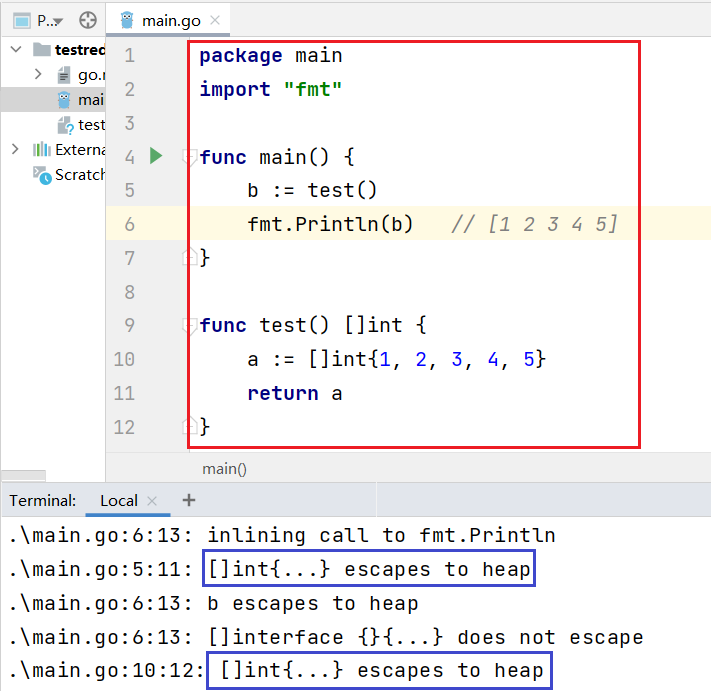
- 函数内部申请的临时变量,正常会分配到栈里,栈中的内存分配非常快,自动回收,无需垃圾回收
- 但是若果申请的临时变量作为了函数返回值,编译器会认为在退出函数之后还有其他地方在引用
- 在编译的时候就会将变量存储到堆中,堆中的数据不会自动回收,必须使用垃圾回收机制清楚
我们将这种 由于某些原因,数据没有分配到栈中而是分配到堆中的现象叫做 内存逃逸
1.2 golang的内存分配之堆和栈
1.2.1 内存分片概述
- Go的垃圾回收,让堆和栈堆程序员保持透明。
- 真正解放了程序员的双手,让他们可以专注于业务,“高效”地完成代码编写。
- 把那些内存管理的复杂机制交给编译器。
- 栈 可以简单得理解成一次函数调用内部申请到的内存,它们会随着函数的返回把内存还给系统。
1.2.2 分配到栈里
- 下面的例子,函数内部申请的临时变量,即使你是用make申请到的内存
- 如果发现在退出函数后没有用了,那么就把丢到栈上,毕竟栈上的内存分配比堆上快很多
func F() {
temp := make([]int, 0, 20)
...
}1.2.3 分配到堆里
- 申请的代码和上面的一模一样,但是申请后作为返回值返回了
- 编译器会认为在退出函数之后还有其他地方在引用,当函数返回之后并不会将其内存归还
- 那么就申请到堆里。
func F() {
temp := make([]int, 0, 20)
...
return temp
}1.3 分配到栈里和堆里区别
- 分片到堆的坏处
- 如果变量都分配到堆上,堆不像栈可以自动清理。
- 它会引起Go频繁地进行垃圾回收,而垃圾回收会占用比较大的系统开销。
- 放到堆还是栈的情况
- 堆适合不可预知的大小的内存分配。
- 但是为此付出的代价是分配速度较慢,而且会形成内存碎片。
- 栈内存分配则会非常快,栈分配内存只需要两个CPU指令:“PUSH”和“RELEASE”分配和释放;
- 而堆分配内存首先需要去找到一块大小合适的内存块。之后要通过垃圾回收才能释放。
02.逃逸的几种情况
2.0 逃逸分析
- 逃逸分析是分析在程序的哪些地方可以访问到该指针。
- 简单来说,
编译器会根据变量是否被外部引用来决定是否逃逸
1、如果函数外部没有引用,则优先放到栈中;
2、如果函数外部存在引用,则必定放到堆中;- 对此你可以理解为,逃逸分析是编译器用于决定变量分配到堆上还是栈上的一种行为。
- 注意:go 在编译阶段确立逃逸,并不是在运行时。
2.1 指针逃逸
方法内把局部变量指针返回- 提问:函数传递指针真的比传值效率高吗?
- 我们知道传递指针可以减少底层值的拷贝,可以提高效率
- 但是如果拷贝的数据量小,由于指针传递会产生逃逸,逃逸可能存储到堆中
- 存储到堆可能会增加GC的负担,所以传递指针不一定是高效的。
2.2 栈空间不足逃逸
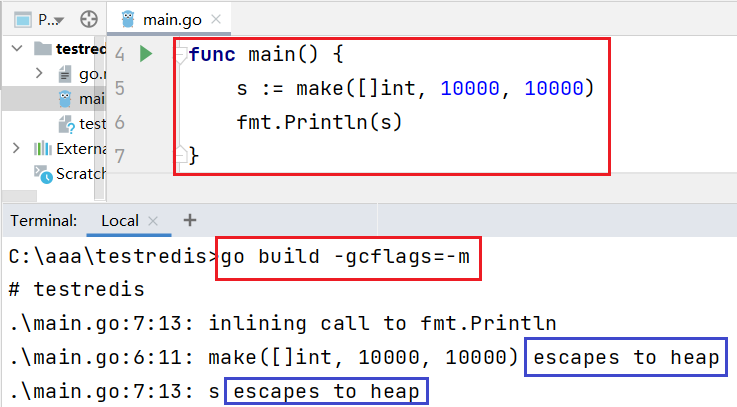
- 当我们创建一个切片长度为10000时就会逃逸。
- 实际上当栈空间不足以存放当前对象时或无法判断当前切片长度时会将对象分配到堆中。
- slice 的背后数组被重新分配了,因为 append 时可能会超出其容量( cap )。
- slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。
- 如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
go build -gcflags=-mpackage main
import "fmt"
func main() {
s := make([]int, 10000, 10000)
fmt.Println(s)
}
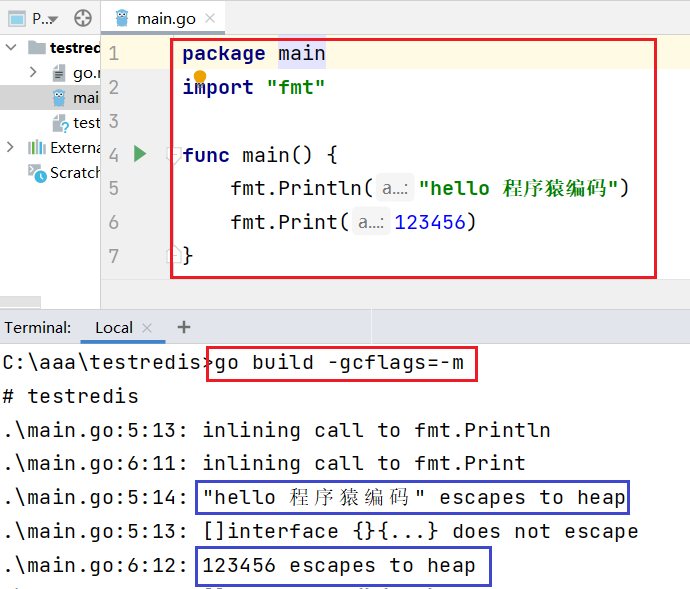
2.3 动态类型逃逸
- 很多函数参数为interface类型,比如 Println函数
func Println(a ...interface{}) (n int, err error)- 编译期间很难确定其参数的具体类型,也能产生逃逸。
03.如何避免
- 1、不要盲目使用变量指针作为参数,虽然减少了复制,但变量逃逸的开销更大。
- 2、预先设定好slice长度,避免频繁超出容量,重新分配。
- 3、如果对于性能要求比较高且访问频次比较高的函数调用,应该尽量避免使用接口类型
- 在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道
04.逃逸分析作用
4.1 逃逸分析作用
- 1、逃逸分析的好处是为了减少gc的压力,不逃逸的对象分配在栈上,当函数返回时就回收了资源,不需要gc标记清除。
- 2、逃逸分析完后可以确定哪些变量可以分配在栈上,栈的分配比堆快,性能好
- 3、同步消除,如果你定义的对象的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
4.2 总结
- 1、堆上动态分配内存比栈上静态分配内存,开销大很多。
- 2、变量分配在栈上需要能在编译期确定它的作用域,否则会分配到堆上。
- 3、Go编译器会在编译期对考察变量的作用域,并作一系列检查
- 如果它的作用域在运行期间对编译器一直是可知的,那么就会分配到栈上。
- 简单来说,编译器会根据变量是否被外部引用来决定是否逃逸。
- 4、不要盲目使用变量的指针作为函数参数,虽然它会减少复制操作。
- 但其实当参数为变量自身的时候,复制是在栈上完成的操作
- 开销远比变量逃逸后动态地在堆上分配内存少的多。
- 5、逃逸分析在编译阶段完成的。
内存逃逸
http://coderedeng.github.io/2021/02/09/Go进阶 - 内存逃逸/